


What Is AI Machine Learning?
Artificial Intelligence and Machine Learning are two of the most transformative technologies of our time. They’re reshaping every industry from healthcare and finance to education and entertainment.
But what exactly is Machine Learning? In simple terms, it is a branch of Artificial Intelligence that enables computers to learn from data without being explicitly programmed for every task. Instead of following fixed rules, a machine learning model identifies patterns, makes predictions, and improves its own performance over time.
| “Machine Learning is not about teaching computers to think like humans. It is about teaching computers to learn like humans — from experience, from data, from mistakes.” |
This guide walks you through everything: how ML actually works, the different types, the algorithms that power it, the real-world applications that are changing lives today, and the ethical questions the industry must confront.
| KEY TAKEAWAYS |
- Machine Learning is a subset of AI that learns from data rather than fixed rules
- There are 3 main types: supervised, unsupervised, and reinforcement learning
- Deep Learning, a subset of ML, powers most cutting-edge AI today
- ML applications span healthcare, finance, cybersecurity, e-commerce, and more
- Ethical concerns like bias and data privacy must be addressed as ML scales
- TensorFlow, PyTorch, and scikit-learn are the dominant ML frameworks in 2026
| $200B+ Global ML Market Size | 85% Enterprises Using AI/ML | 10x Faster Decision Making | 97% Accuracy: Top ML Models |
How Machine Learning Works
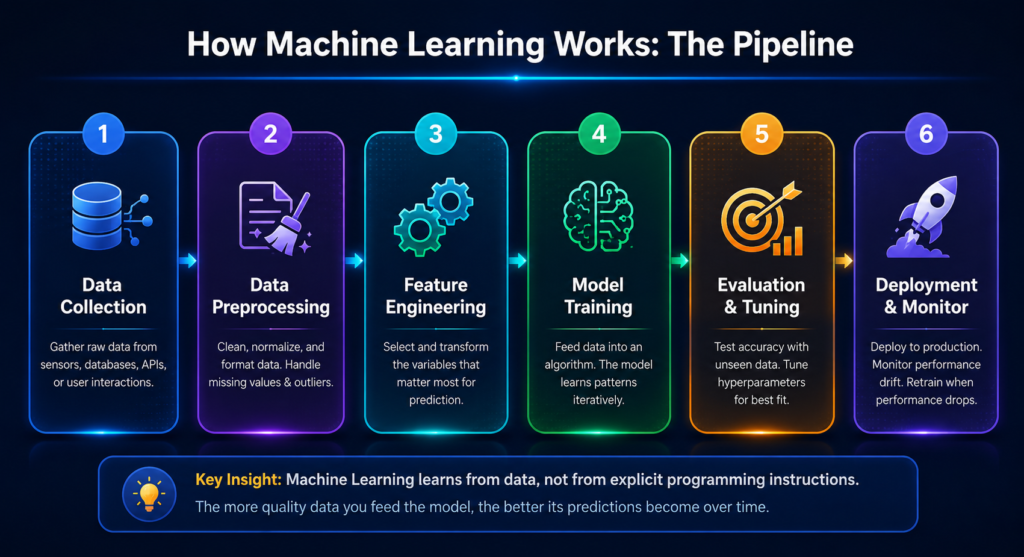
At its core, Machine Learning follows a consistent pipeline regardless of the specific algorithm or problem. Understanding this pipeline is the key to understanding how any ML system operates.
The process starts with data. Raw, unstructured information from the real-world sensor readings, transaction records, images, text, and audio. Without data, there is no learning. The quality and quantity of your data largely determine the quality of your model.
Next comes preprocessing. Real-world data is messy. Values are missing. Formats are inconsistent. Noise drowns out signals. Preprocessing cleans and structures the data so algorithms can work with it efficiently.
Then comes the training phase. The algorithm is fed the preprocessed data and begins identifying patterns. In supervised learning, it compares its predictions to known correct answers and adjusts itself to reduce errors. This iteration happens thousands or millions of times.
Once trained, the model is evaluated on data it has never seen before. This reveals how well it generalizes whether it has learned real patterns or just memorized the training data (a problem called overfitting).
Finally, the model is deployed into production, where it makes real predictions in real time. But the job is never done. Models degrade as the real world changes. Continuous monitoring and periodic retraining are essential.
| KEY CONCEPT: Overfitting vs Underfitting Overfitting: The model memorizes training data but performs poorly on new data. Underfitting: The model is too simple to capture the underlying pattern. The goal is finding the sweet spot a model that generalizes well to unseen data. |
The Machine Learning Pipeline
The 3 Main Types of Machine Learning
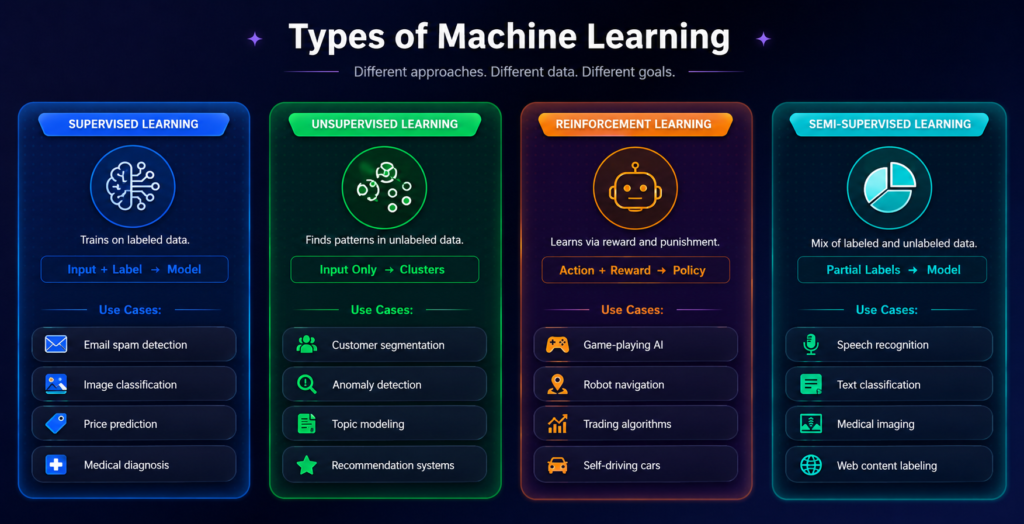
Not all Machine Learning works the same way. The approach used depends on the type of data available and the problem being solved. There are three primary categories.
1. Supervised Learning
Supervised learning is the most widely used form of ML. The algorithm trains on a labeled dataset meaning each training example is paired with the correct answer. The model learns the mapping between inputs and outputs, then applies that mapping to new, unseen data.
Think of it like a student learning from a textbook with an answer key. You show the model thousands of emails labeled as spam or not spam. It learns which features certain words, sender addresses, and formatting patterns predict each label. Then it classifies new emails on its own.
Common applications: Email spam detection, image classification, medical diagnosis, credit scoring, price prediction, and natural language processing.
2. Unsupervised Learning
Unsupervised learning works with unlabeled data. There are no pre-assigned answers. The algorithm’s job is to discover hidden structure, patterns, or groupings within the data on its own.
This is valuable when you don’t know what you’re looking for. A retailer might feed purchase history into an unsupervised algorithm and discover natural customer segments, high-value loyalists, bargain hunters, and seasonal shoppers that nobody had defined in advance.
Common applications: Customer segmentation, anomaly detection, topic modeling, recommendation engines, and data compression.
3. Reinforcement Learning
Reinforcement learning takes a completely different approach. An agent interacts with an environment, taking actions and receiving rewards or penalties based on the outcomes. Over time, it learns which actions lead to the best long-term rewards.
This is how DeepMind’s AlphaGo learned to beat world champion Go players. It played millions of games against itself, learning which moves led to victory through trial and error, not from a labeled dataset of winning moves.
Common applications: Game-playing AI, robotic navigation, autonomous vehicles, algorithmic trading, and drug discovery optimization.
| BONUS: Semi-Supervised Learning A fourth type combines both approaches. It trains on a small amount of labeled data and a large amount of unlabeled data. This is especially useful when labeling data is expensive or time-consuming, for example, in medical imaging, where expert annotation costs thousands of dollars per scan. |
Types of Machine Learning
AI vs Machine Learning vs Deep Learning
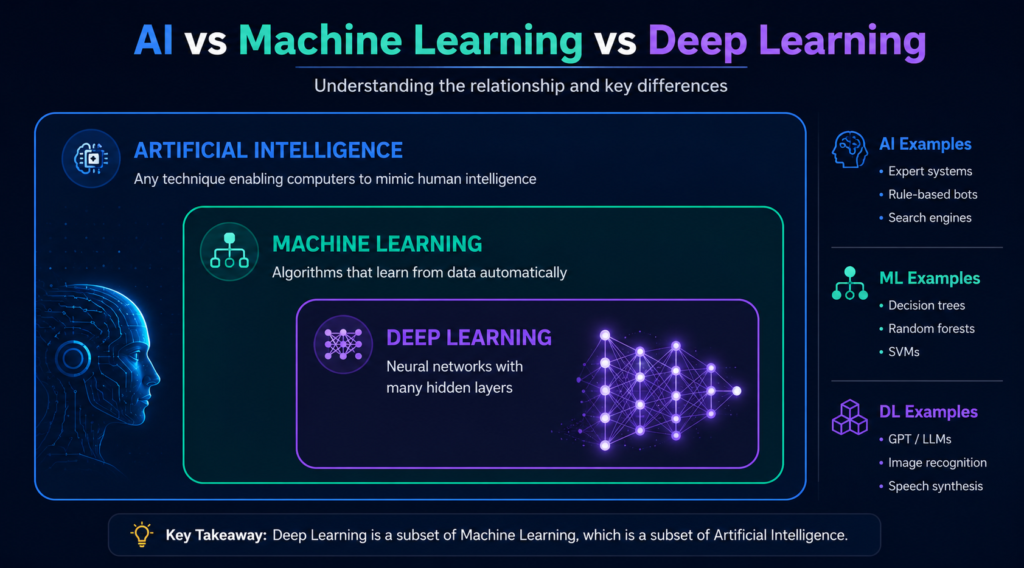
These three terms are often used interchangeably but they mean very different things. Understanding the distinction is fundamental to understanding the field.
- Artificial Intelligence (AI) is the broadest concept. It refers to any technique that enables computers to mimic human intelligence. This includes everything from simple if-then rule systems to the most advanced neural networks. AI is the goal.
- Machine Learning (ML) is a subset of AI. It is the specific approach of enabling computers to learn from data, rather than following hand-coded rules. ML is the method.
- Deep Learning (DL) is a subset of ML. It uses neural networks with many hidden layers. ‘Deep’ refers to the depth of these layers. Deep Learning powers most modern AI breakthroughs: ChatGPT, image recognition, real-time translation, speech synthesis. DL is the current engine of progress.
A useful analogy: All Deep Learning is Machine Learning. All Machine Learning is AI. But not all AI is Machine Learning, and not all Machine Learning is Deep Learning.
Top Machine Learning Algorithms
Machine Learning is powered by dozens of algorithms. Each has strengths and weaknesses the right choice depends on the problem, the data type, the required accuracy, and how much interpretability matters. Here are the six most important ones.
Linear Regression
The simplest and most interpretable ML algorithm. It finds the best straight line through a set of data points to predict a continuous output variable. Want to predict house prices based on size and location? Linear regression is often your first step.
Decision Tree
A tree-like model that makes decisions by splitting data into branches based on feature values. Each leaf node represents a class label or prediction. Decision trees are highly interpretable you can read exactly why a model made a specific decision.
Random Forest
An ensemble method that builds hundreds of decision trees and combines their predictions. This dramatically reduces overfitting and improves accuracy. Random forests power many fraud detection and medical diagnosis systems today.
Support Vector Machine (SVM)
SVM finds the optimal boundary (hyperplane) between classes in high-dimensional space. Excellent for text classification and image recognition tasks, especially with small to medium datasets.
Neural Networks
Inspired by the human brain, neural networks consist of layers of interconnected nodes. Deep neural networks with many hidden layers are what power modern AI. They can learn extraordinarily complex patterns from raw data: images, audio, text, and video.
K-Means Clustering
An unsupervised algorithm that groups data points into K clusters based on similarity. Simple, fast, and highly effective for customer segmentation, document clustering, and anomaly detection.
| Algorithm | Accuracy | Explainability | Speed | Best For |
| Linear Regression | 9/10 | 9/10 | 9/10 | Predicting prices, scores, continuous values |
| Decision Tree | 7/10 | 8/10 | 8/10 | Classification tasks with interpretable rules |
| Random Forest | 9/10 | 6/10 | 7/10 | High accuracy ensemble — fraud detection, medicine |
| SVM | 8/10 | 5/10 | 7/10 | Text classification, image recognition |
| Neural Network | 10/10 | 3/10 | 6/10 | Complex pattern recognition, generative AI |
| K-Means | 7/10 | 8/10 | 9/10 | Customer segmentation, anomaly detection |
Real-World Applications of Machine Learning
Machine Learning is no longer confined to research labs. It is embedded in the products and services billions of people use every day. Here is how it is transforming the most important industries.
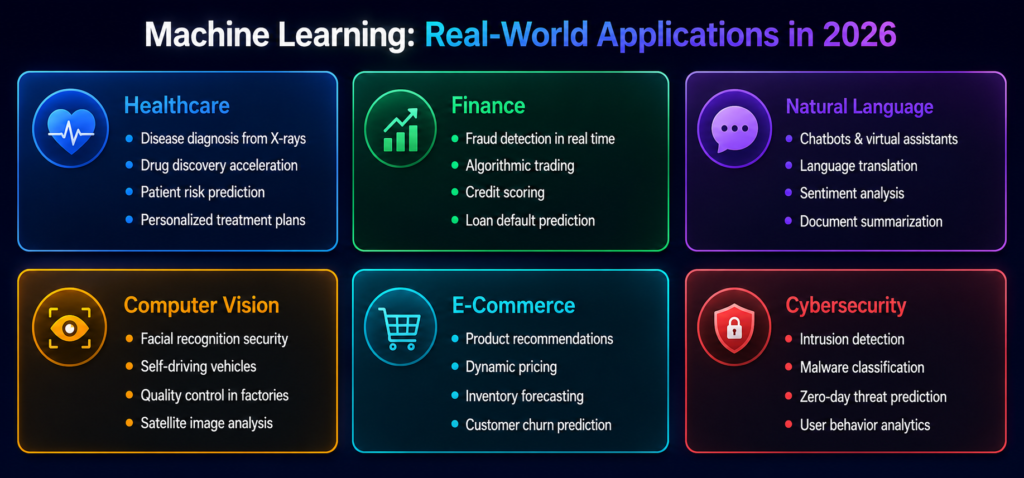
Healthcare
ML models can now detect cancer in medical images with accuracy matching or exceeding that of experienced radiologists. Drug discovery timelines traditionally measured in decades are being compressed to years. Predictive models assess patient readmission risk, enabling earlier intervention. Personalized treatment recommendations are generated based on a patient’s genetic profile and medical history.
Finance & Banking
Banks use ML to detect fraudulent transactions in real time analyzing hundreds of data points per transaction in milliseconds. Credit scoring models assess default risk more accurately than traditional methods. Algorithmic trading systems execute millions of trades per second based on ML-driven market signals.
Natural Language Processing
NLP is one of the most visible faces of ML today. Every time you use a voice assistant, get a translation, receive a chatbot response, or read an AI-generated article summary, ML is doing the work. Large Language Models (LLMs) like GPT-4 represent the current frontier, trained on hundreds of billions of words to generate human-like text.
Computer Vision
ML-powered vision systems can classify objects in images, detect faces, read text from photos, and analyze video in real time. Self-driving vehicles rely on computer vision to perceive and navigate the physical world. Factories use vision systems for automated quality control, catching defects that human inspectors would miss.
Cybersecurity
Traditional signature-based security tools can only catch known threats. ML-based security systems detect anomalies in network traffic, user behavior, and system calls, identifying novel attacks before they cause damage. This is increasingly critical as cyber attacks grow more sophisticated.
Top ML Frameworks and Tools in 2026
You don’t build Machine Learning from scratch. Powerful open-source frameworks do the heavy lifting, providing optimized implementations of algorithms, automatic differentiation, GPU acceleration, and deployment tools.
| TF Python | TensorFlow Google’s flagship ML framework. Powers production ML at Google Search, Google Translate, and YouTube recommendations. Excellent for deep learning at scale, with strong deployment tools via TensorFlow Serving and TensorFlow Lite for mobile. Used by: Google, Airbnb, Twitter, Intel, NASA |
| PT Python | PyTorch Meta’s research-first framework that became the dominant choice for AI researchers. An intuitive dynamic computation graph makes debugging and experimentation fast. Most cutting-edge research papers release code in PyTorch first. Now dominant in academia and fast-growing in production. Used by: Meta, Tesla, Uber, Microsoft, OpenAI |
| SK Python | Scikit-learn The gold standard for classical ML algorithms. Linear regression, decision trees, random forests, SVMs, and clustering are all implemented with a consistent, clean API. Not suited for deep learning, but indispensable for traditional ML workflows and rapid prototyping. Used by: Spotify, JP Morgan, Booking, Inria |
| HF Python | Hugging Face The central hub for pre-trained models and NLP tooling. Provides thousands of pre-trained transformers, BERT, GPT, and LLaMA, ready to fine-tune on custom datasets. In 2026, Hugging Face has become the App Store of AI models. Used by: Bloomberg, Writer, Grammarly, AWS |
ML Algorithm Comparison Chart

Ethics, Bias, and the Responsible Use of ML
Machine Learning is only as good — and as fair — as the data it learns from. When training data reflects historical biases, the model will replicate and often amplify them. This is not a hypothetical concern.
Facial recognition systems have demonstrated significantly higher error rates for darker skin tones. Hiring algorithms trained on historical data have discriminated against women applying for technical roles. Credit scoring models have disadvantaged certain zip codes and demographic groups.
| CRITICAL CONCERN: Algorithmic Bias ML bias is not always intentional it emerges from skewed training data, biased feature selection, or flawed evaluation metrics. Addressing it requires diverse development teams, rigorous bias auditing, and ongoing monitoring after deployment. Regulations in the EU (AI Act 2024) and emerging US frameworks are beginning to mandate transparency and accountability. |
Data privacy is the second major ethical challenge. ML models are hungry for data, and that data often comes from people who did not explicitly consent to its use in model training. The right to explanation (why did the algorithm make this decision?) and the right to opt out are active policy debates in 2026.
Explainability is the third pillar. Deep learning models are often ‘black boxes’; they produce accurate predictions but cannot explain their reasoning in human terms. In high-stakes domains like medicine, finance, and criminal justice, a model that cannot explain itself is a model that cannot be trusted or audited.
The Future of Machine Learning
We are still in the early innings of the ML revolution. The next decade will bring changes that are difficult to fully anticipate, but several clear directions are already visible.
Foundation Models and Generative AI
The rise of large foundation models trained on massive, diverse datasets and fine-tuned for specific tasks has fundamentally changed how ML is deployed. Rather than training specialist models from scratch, organizations now fine-tune pre-trained models. GPT-4, Claude, Gemini, and LLaMA represent the current state of the art. The next generation will be more capable, more efficient, and more multimodal.
Edge AI and On-Device Learning
Increasingly, ML inference is moving from cloud data centers to the devices themselves, smartphones, wearables, autonomous vehicles, and industrial sensors. On-device ML eliminates latency, reduces bandwidth costs, and addresses privacy concerns by keeping data local. Apple’s Neural Engine and Qualcomm’s AI chipsets are already enabling powerful on-device ML today.
AutoML and Low-Code AI
AutoML platforms automate the selection and tuning of ML models, making ML accessible to domain experts without deep programming knowledge. A medical researcher can now build a diagnostic model without writing a line of code. This democratization of ML will dramatically expand the pool of practitioners and the range of problems being solved.
Quantum Machine Learning
This computing promises to solve optimization problems that are intractable for classical computers, and optimization is at the heart of ML training. Quantum ML is still largely experimental in 2026, but Google, IBM, and D-Wave are investing heavily. Within a decade, quantum acceleration could make current ML training times look glacial.
Final Thoughts
Machine Learning is not a trend. It is a fundamental shift in how computers work and how problems get solved. The transition from rule-based programming to data-driven learning is as significant as the move from manual calculation to digital computing.
The technology is already transforming medicine, finance, communication, transportation, and security. Over the next decade, it will reach into virtually every domain of human activity, from climate modeling to personalized education to scientific discovery.
But with that power comes responsibility. Bias, privacy, and explainability are not edge cases; they are central challenges that require deliberate engineering, thoughtful policy, and ongoing public scrutiny. Understanding Machine Learning, at least at a conceptual level, is becoming a basic literacy requirement for professionals in every field. This guide is your starting point.
Frequently Asked Questions
What is the difference between AI and Machine Learning?
Artificial Intelligence is the broad goal of making computers perform intelligent tasks. Machine Learning is one specific approach to achieving that goal by training models on data rather than programming explicit rules. All Machine Learning is AI, but not all AI uses Machine Learning.
Do I need to know math to learn Machine Learning?
A solid understanding of linear algebra, calculus, and probability theory helps significantly when learning ML deeply. However, modern frameworks like scikit-learn and TensorFlow handle the heavy math. Many practitioners start with Python and high-level libraries, then fill in the mathematical foundations over time.
What programming language is best for Machine Learning?
Python is the dominant language for ML by a wide margin thanks to libraries like TensorFlow, PyTorch, scikit-learn, NumPy, and pandas. R is popular in academic and statistical contexts. Julia is growing for high-performance scientific computing. If you are starting, Python is the clear choice.
How much data do you need to train a Machine Learning model?
It depends entirely on the problem complexity and the algorithm used. Simple linear regression can work with hundreds of examples. Deep learning models for image recognition typically need thousands to millions of labeled examples. Transfer learning starting from a pre-trained model dramatically reduces data requirements.
What is the difference between Machine Learning and Deep Learning?
Deep Learning is a subset of Machine Learning that uses neural networks with many hidden layers. All Deep Learning is Machine Learning, but not all Machine Learning uses deep neural networks. Classical ML algorithms like decision trees and SVMs are powerful and often preferable for structured data, while Deep Learning excels at unstructured data like images, audio, and text.
Can Machine Learning models be wrong or biased?
Yes — and this is one of the most important challenges in the field. ML models learn from training data. If that data reflects historical biases or is unrepresentative of the real world, the model will replicate those biases. Rigorous data auditing, diverse development teams, and post-deployment monitoring are all essential safeguards.
What are the best resources to learn Machine Learning in 2026?
Andrew Ng’s Machine Learning courses on Coursera are the gold standard starting point. Fast.ai offers an excellent practical approach. Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow by Aurelie Geron remains the best book for practitioners. Kaggle competitions provide real-world practice with competitive benchmarking.